
The Ringmaster Problem
Why more AI should mean more humans, not fewer, and what the Starbucks case should have taught us about human-machine amity.

Image created with AI tools
In September 2025, Starbucks released a short promotional video to celebrate the launch of an AI-powered inventory system that the company had built in partnership with the computer vision startup NomadGo. The tool was positioned as a centerpiece of CEO Brian Niccol’s “Back to Starbucks” turnaround, a strategy designed to address the persistent product shortages that had been quietly eroding customer experience and same-store sales for years. The video showed a barista walking through a back room with a handheld tablet, sweeping the camera across shelves of milks and syrups while the system tagged and counted each item in real time. In one of the frames of that very video, the system failed to register a bottle of peppermint syrup that was sitting on the shelf in plain view, surrounded by other bottles that the system did correctly identify. Nobody at Starbucks caught the error before the video shipped, the blog post went live, and the rollout began across more than eleven thousand North American stores.
Eight months later, in May 2026, Starbucks quietly retired the system across the entire fleet, the original blog post was deleted from the corporate site, and the promotional video was pulled from circulation. The story made the trade press as a tidy AI failure narrative, with most coverage focusing on the technical embarrassment of a system that could not reliably distinguish oat milk from regular milk. What almost none of the coverage took seriously was the workforce story sitting underneath the technical one, and I want to tell that part here because I think it is the part that actually matters for every leader trying to navigate this moment.
The Starbucks partners, the workers on the floor who interact with these systems every day, did not trust the AI from very early in the rollout. They scanned the shelves with the tablet because they were required to, they watched the system return its counts, and then they quietly recounted by hand and entered the corrected numbers into the inventory log. They protected the stores from the AI’s errors for nine months by absorbing the extra workload onto themselves, working a second shift of verification on top of the work they were already doing. They are the reason the failures stayed mostly invisible to customers and to corporate leadership until the system was finally pulled, and they are also, in the same breath, the people the broader industry narrative is currently lining up to lay off in the name of AI productivity. That contradiction sits at the center of the AI adoption wave, and I want to name it as clearly as I can in what follows.
The Wrong Frame
The dominant story in the current AI moment is that humans and machines are competing for the same jobs, with the AI either taking the job from the human or the human keeping the job until the AI is good enough to take it. Either way, the relationship is framed as a contest with one winner and one loser, and the entire vocabulary of “AI productivity” has been built on top of that framing. This frame is wrong both technically and organizationally, and the Starbucks case shows you exactly why with a level of clarity that few cases offer.
The AI inventory tool did not do the partners’ job, even on the days when it worked. It did one slice of the partners’ job, which was the visual identification of products on a shelf, and it did that slice badly under the operational conditions of a real back room. The other slices of the job, including knowing yesterday’s shipment patterns, knowing which products burned through fastest during the morning rush, knowing which carton was tucked behind another because the closing shift had restocked in a hurry, and owning final accountability for the count when the day’s numbers were reconciled, were never part of what the AI could do and were never part of what the system was designed to do. Those slices remained with the human partner, who now held less authority over the visible counting work and the same responsibility for the eventual outcome, which is the worst possible position to put a worker in if you actually want the system to succeed.
This is not automation in any meaningful sense of the word. This is cognitive load transfer dressed up in the vocabulary of cost reduction, where the easy and legible part of a job gets handed to a machine while the hard and illegible parts get concentrated onto fewer remaining people who now have less context, less authority, and less protection from the consequences of the machine’s mistakes. The conversation we should be having is not whether to lay off the inventory counters because the AI can count, but rather what the expanded human role looks like around a partially automated process, and how many people we need in that expanded role for the system as a whole to actually work. That question is almost never asked in the rooms where AI procurement decisions get made, and so I want to ask it here with as much specificity as I can.
What If: A Manual Monte Carlo
Before I lay out the scenarios, let me say what I mean by a manual Monte Carlo. In quantitative finance and in operations research, a Monte Carlo simulation is a method of exploring possible futures by running the same model thousands of times with different inputs and watching the distribution of outcomes that emerges from the variability. You cannot do this on paper at scale, but you can do a slower and more deliberate version of the same thinking by hand, by asking what-if questions one at a time and walking each scenario out to its consequences before deciding which path to actually take. This is the kind of exercise that every leadership team should be running before they sign an AI contract, and the absence of this exercise is one of the most consistent features of the AI failures we have seen so far.
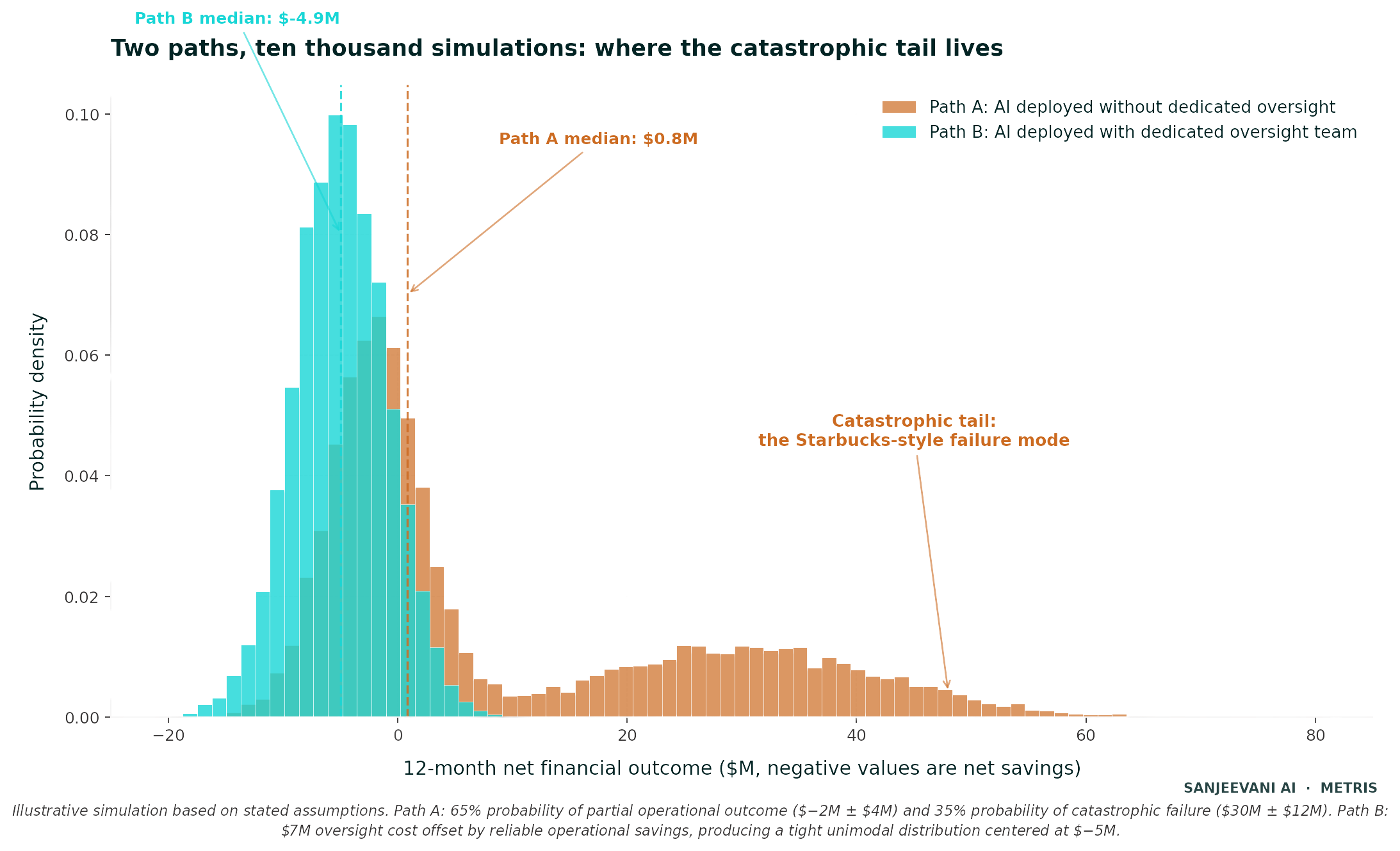
Image generated using python code by the author
Let me run five of these scenarios for the Starbucks case, not as predictions and not as numbers I could defend inside a formal model, but as the kind of structured thinking that the rollout itself appears to have skipped. I have begun to refer to this approach as a manual Monte Carlo for AI governance decisions, and the five scenarios that follow are the practical instrument I use when thinking about whether a given AI deployment is genuinely ready to ship into the operational world it will actually have to survive in.
The first scenario asks what would have happened if Starbucks had kept every partner on the floor and added a dedicated AI oversight team alongside the rollout. Imagine a team of perhaps fifty to one hundred people whose only job is to audit AI output against ground truth across the eleven thousand store fleet, sampling stores on a rotating schedule, reviewing confidence score distributions, identifying model drift before it becomes catastrophic, and feeding human corrections back into a retraining pipeline that updates the model on a regular cadence. The annual cost of such a team would be real, perhaps in the range of five to ten million dollars when fully loaded with engineering support and infrastructure, and it would be dwarfed by the cost of a failed nine-month rollout across eleven thousand locations, even before you begin to count the brand damage, the deleted blog post, the loss of internal credibility for the next AI initiative, and the harder-to-measure erosion of trust between partners and the corporate technology function. The deeper point, the one that matters more than the headcount or the budget, is that an oversight team of this kind functions as a forcing function for everything else the deployment should have included from the start, because the very existence of a paid oversight function makes engineering hygiene mandatory rather than optional. Without a budget line for oversight, the engineering team naturally optimizes for the demo and the ship date, since nobody inside the company is being paid to demand the audit trail, the retraining cadence, the rollback authority, or the operational testing protocol. With a budget line for oversight, the team’s first ninety days of work would surface exactly those missing pieces and would force the rest of the organization to build them, because the oversight function cannot do its own job without them. My own view, which I hold with some confidence after watching enough of these rollouts up close, is that this first scenario is the single highest-leverage intervention of the five I am about to walk through, because it creates the institutional pressure that pulls the other four into place behind it almost automatically. If Starbucks had committed to this one structural choice alone and had held the rest of the rollout to whatever pace the oversight team could actually validate, I believe the system would still be running today in a meaningfully better form than it ever achieved during its actual nine-month life.
The second scenario asks what would have happened if the partners themselves had been trained to interpret the AI’s confidence scores rather than being shown only the final classification. A two-day training program could have taught every partner in every store what a confidence score is, what it means when the tablet reports that an item was identified with 0.62 confidence versus 0.94 confidence, and how to decide whether to trust the AI’s count or recount manually based on that signal. The system would stop pretending to be certain when it was not, the partner would have a clear and defensible rule for when to intervene, the second shift of silent verification would become a deliberate and trained workflow rather than a hidden burden, and the partner would emerge from the deployment more skilled and more valuable to the company than they had been before it began. The analysis that needs to be done honestly here, however, is the one that asks whether the training alone would have changed actual behavior in the morning rush of a real store, and my view is that it would not have, at least not by itself, because reading a confidence score does no good if the worker has no operational permission to act on it. If the partner is still being measured on completing back-of-house tasks within a fixed time window, if the manager is still scheduling the shift around an assumption that inventory takes thirty minutes rather than the forty-five minutes it would take with proper verification, and if the performance review structure still rewards speed over accuracy, then the partner will see the 0.62 confidence score and will accept the count anyway, because slowing down to recount is a behavior the organization has not actually made room for. The training has to be paired with management metrics that explicitly reward verification over speed, and with shift scheduling that accommodates the time verification requires, otherwise the training becomes a polite fiction layered on top of an unchanged operational system. My opinion on this scenario is that it is useful as a complement to the first one but dangerous as a standalone fix, because it places the cognitive burden of catching AI errors back onto the worker without giving them the time, the authority, or the metric structure to discharge it well, and the worker is left in essentially the same position they were already in during the actual rollout, except now they are also responsible for understanding a confidence score on top of everything else they were already doing silently.
The third scenario asks what would have happened if every AI rollout in the company had been paired with a human oversight structure scaled to the size of the deployment, in the way that every other safety-critical system in the modern economy is paired with its corresponding human oversight function. Airplanes have pilots in the cockpit and air traffic controllers in the tower, power grids have local operators and regional supervisors who coordinate across the network, hospitals have clinicians at the bedside and quality review boards in the institutional governance layer, and each of these structures exists because we have learned over decades that complex technical systems do not stay safe or accurate without continuous human attention to their behavior. AI deployment, with stakes that increasingly rival these other systems, currently ships without any analogous oversight function in the vast majority of cases, not because the need is unknown but because nobody put a line item for it in the original procurement proposal and no buyer thought to ask why it was missing. The historical analysis that needs to be done honestly here is that each of these oversight structures came into existence reactively rather than proactively, after the industry had paid in lives or in losses for not having the structure already in place, with the Tenerife runway collision shaping the modern shape of air traffic control, the Three Mile Island incident shaping the modern shape of nuclear plant operations, and the Institute of Medicine reports of the late 1990s shaping the modern shape of hospital quality and safety. AI as a category of technology is currently in what I would describe as the pre-Tenerife phase of its lifecycle, by which I mean that the catastrophic failure which will eventually mandate the oversight structure has not yet happened in a form severe enough to force regulatory action across the entire industry, and the rollouts of the next two to three years are quietly building toward the kind of incident that will produce that mandate. My opinion on this scenario, and the one I would most want a board of directors to sit with for the longest time, is that the oversight structure is historically inevitable and that the only meaningful executive choice available right now is whether to build it voluntarily and proactively with room to design it thoughtfully and capture its benefits, or to be forced into building it reactively later under regulatory pressure and after the company has already become the cautionary tale that other companies study. The executives who choose voluntarily now will be the ones cited in five years as the responsible early operators of this technology, and the ones who skip it will be in the case study deck that the next generation of business school students will be required to read.
The fourth scenario asks what would have happened if the workforce story had been told to the partners and to the public in honest terms from the start. Imagine the announcement reading something like this: we are deploying AI in our back rooms, we are not reducing headcount in connection with this rollout, we are expanding the role of every partner to include AI verification and feedback, and we are hiring a new class of AI quality engineers to support that expanded role. This is the story that most companies are unwilling to tell because it does not fit the cost-cutting deck the CFO needs for the next earnings call, but it is also the story that would have given the partners a reason to be invested in the system’s success rather than skeptical of its motives, and it would have surfaced the operational realities of the back room into the design process months before the system shipped. The harder analysis that has to be done honestly here is the one that asks why no executive is currently telling this story even when they privately believe it, and my view is that the answer is not a personal failing on the part of the executives but rather a coordination problem at the level of the market itself. The current investor narrative around AI rewards companies that signal headcount reduction in connection with AI deployment, regardless of whether the AI is actually replacing the underlying work, which means the chief executive who tells the honest story takes a real stock price hit from the same investors who are funding the AI deployment in the first place. This is the trap that most public company executives are sitting inside right now, and the trap will not release until enough boards begin to realize that the dishonest story is what is producing the Starbucks pattern at the operational layer, and that the operational pattern is what is eventually destroying the value the AI rollout was supposed to create in the first place. My opinion on this scenario is that it is the hardest of the five to execute even when leadership privately wants to do it, because it requires bucking the entire current investor mood at the same moment that the investor mood is funding the AI strategy, and that this scenario will become executable at scale only when enough articles like the one you are reading right now help to seed the realization that is currently missing from the boardroom conversation. The piece in your hands is, in that limited sense, a small contribution to making this fourth scenario eventually possible.
The fifth scenario asks what would have happened if executives had drawn the line at the contract stage rather than after the failure was already visible. No AI deployment should be approved without explicit answers to a small number of governance questions, including who is accountable when the AI is wrong, what the confidence threshold is for autonomous action, what the rollback trigger looks like and who has the authority to pull it, who owns the human oversight team and where they sit in the org chart, what the retraining cadence will be and what the feedback loop is from worker corrections back into the model, and what the operational testing protocol is for the conditions under which the system will actually be used. Most AI contracts today are signed without any of these answers on the table, with the procurement process treating AI as if it were ordering office furniture, and the predictable result is that the answers get discovered the hard way, in production, after the system has already been deployed at scale. The structural analysis that has to be done honestly here is that the reason these questions almost never get asked in procurement is not because the buyer does not care, but because the buyer does not yet have the framework to know which questions are the important ones, the vendor does not volunteer the questions because they extend the sales cycle, and the legal team is checking standard contractual boilerplate rather than AI-specific governance language. Until procurement teams across industries have a shared rubric for AI contract due diligence, every individual deployment will reinvent these questions on its own and most will reinvent them badly or incompletely, which is the pattern we are watching play out in real time across the early enterprise rollouts of this technology. My opinion on this scenario is that it is the place where regulation will eventually arrive, because the market is not going to solve the problem on its own at anything close to the speed at which the technology is being deployed, and we are already seeing the early shape of that regulatory move in places like the recent FDA guidance for the use of AI in pharmaceutical quality systems, where the agency has now stated on the record that the company holds the liability regardless of whether the failure originated in an AI tool or in a human consultant. The executive who treats AI procurement today with the same diligence they would apply to the hiring of a senior consultant or to the qualification of a critical supplier is doing voluntarily what they will very soon be required to do anyway by their regulators, by their auditors, and by their insurers, and the gap between the voluntary adopters and the forced adopters is going to be one of the defining competitive lines of the next three years.
These five scenarios are not equally easy to execute, as the analysis I have walked through tries to make plain, and I want to be honest about the fact that the first one is the structural lever that pulls the others into place, the second one is dangerous in isolation though valuable as a complement, the third one is historically inevitable and the only real question is voluntary or forced, the fourth one is the hardest cultural lift because it requires bucking the investor narrative at the moment that narrative is funding the deployment, and the fifth one is where regulation will eventually arrive whether the industry is ready for it or not. What is shared across all five, and what makes them worth thinking about together rather than choosing among in isolation, is that each of them costs more in the short term than the path Starbucks actually took, and each of them, when you sit with the math honestly, costs far less in the long term and produces an AI deployment that actually achieves the operational outcome the technology was bought for, without quietly transferring the failure modes onto the workforce the company is simultaneously planning to lay off. The math is not the obstacle here. The thinking is.
The Roles, Properly Defined
The framing I want to argue for, and the framing that should sit at the center of every AI deployment decision going forward, is that humans and machines do not compete for the same role in a well-designed system because they are structurally suited to different roles. Machines are extremely good at pattern recognition across very large numbers of inputs, at repetition without fatigue across long time horizons, at computation that exceeds human speed by many orders of magnitude, at consistency on inputs that resemble the data they were trained on, and at operating across all twenty-four hours of the day without the breaks that human bodies require. These are real and valuable capabilities and there is no honest case for ignoring them in modern operations. Humans, in turn, are extremely good at integrating context that the machine never saw and could not have seen, at exercising judgment on novel situations that fall outside the training distribution, at maintaining calibrated awareness of their own uncertainty and communicating that uncertainty honestly to others, at making ethical decisions where the stakes are not encodable in a loss function, at holding accountability when the system errs in ways that affect real customers and real outcomes, at remembering past failures and the causes that produced them so that the same failure does not happen again, and at the deeply skilled work of training and supervising and correcting the machines themselves.
Notice what happens to the human role in a system that takes both lists seriously. As the machines do more of the work they are well suited for, the human role does not shrink, it changes shape and in most cases becomes more demanding rather than less. The human becomes the ringmaster who coordinates the system, the watchman who monitors its behavior, the trainer who feeds it new data and corrects its drift, the verifier who checks its outputs against ground truth, the loop-closer who turns every failure into an institutional learning, and the accountable party who answers for the system when something goes wrong in front of a customer or a regulator. These roles are not less skilled than the work the AI displaced, they are more skilled and more cognitively demanding, and they require deliberate investment in training programs and in headcount budgets and in career paths that did not exist in the pre-AI version of the organization.
If you are deploying AI seriously, you should expect your workforce composition to shift in shape rather than to shrink in size. You will have fewer people doing the specific task the AI now performs, and you will have more people doing the work the AI cannot do, which includes the supervision of the AI itself and the integration of its output into the broader context of the organization’s actual operations. A board of directors that approves an AI deployment with simultaneous layoffs in the same department is not making a productivity decision, regardless of how the decision is dressed for the earnings call. They are telling you plainly that they do not understand what they have just bought, and the cost of that misunderstanding will land somewhere in the organization eventually, usually on the customers and the workers who remain.
Human-Machine Synergy
In October 2024, I published a book titled The AI-Human Synergy: A Data Scientist’s Vision for the Future, in which I argued that the future of work is not a story of humans being replaced by machines but a story of humans and machines entering deliberate and complementary partnership, with each side doing what each is genuinely good at, each side compensating for the other’s blind spots, and each side accountable for the part of the work that only that side can do. The argument was meant to be a corrective to a public conversation that had already begun to slide into a binary framing of replacement versus survival, and it was rooted in the observation, from my own twenty-five years across education and research and applied data science, that the systems which actually work in the real world are almost always the ones designed around this kind of partnership rather than around the fantasy of full automation.
We are not yet living in the world that book describes. We are living instead in a transitional moment where companies are buying AI as if it were a workforce replacement, deploying it as if it were proven, laying off workers as if the deployments had succeeded, and then quietly retiring the systems eighteen months later when the failures become impossible to hide any longer. The Starbucks case is one example of this pattern, and it will not be the last one. There are several more in motion right now that will reach the trade press over the next twelve months, and the underlying dynamics will be recognizable in every one of them once you know what to look for. In the broader work I am leading at SANJEEVANI AI to build quantitative trust measurement infrastructure for enterprise AI deployments, this five-scenario lens is one of the components that feeds into a larger architecture for evaluating whether an organization is genuinely ready for the AI it is in the process of buying.
What I am calling for in this article, and what I think every executive in a position to draw this line should be calling for in their own organizations, is a different posture toward AI deployment that is neither anti-AI nor pro-layoff but rather pro-design, in the sense of designing the human-machine system on purpose rather than allowing it to emerge by accident from the collision of vendor sales decks and CFO spreadsheets. Defining the roles deliberately, building the oversight structure to match the deployment size, training the humans for the new and more demanding roles they are being asked to occupy, and hiring more of them in different roles to do the work the AI cannot do, all of this is the actual work of what I have been calling human-machine amity, and it is harder than firing people because it requires the organization to think clearly about what its own jobs actually are. It is also, and this is the part that should matter to the people who hold the budgets, the only path that delivers the productivity gains the technology is genuinely capable of producing.
The Starbucks partners knew what their job actually was, the AI did not know what the job was because it had never been told and could not have been told within the structure of the deployment as it was designed, and the executives somewhere in the middle of those two ends of the system mistook the visible surface of the work for its actual substance. That is the mistake that is being made at scale, in industry after industry, in the rollouts happening right now in 2026, and it is a mistake that we have every technical and organizational capability to correct if we are willing to do the harder thinking it requires. The next phase of this conversation, and the one I believe the field has to move into over the next two to three years, is not just better thinking about these tradeoffs but the construction of measurable infrastructure that quantifies them before deployment rather than discovering them after, and that direction of work is exactly where I am committing my own time. We can do this differently, and given what is now on the line for workers and for customers and for the credibility of AI as a category of technology, I would argue that we have to.
Read this, ponder it, sit with it, and bring it into the next AI conversation you find yourself in this week, whether that is a board meeting, a procurement call, a hallway conversation with a worker on your team, or a quiet moment of your own thinking. I am writing this as a businesswoman who is building toward a future where AI and humans work in deliberate partnership, not as a critic standing outside the field throwing stones. The companies that get this right over the next three years will be the ones still standing in 2030, and the work of getting it right starts with the kind of structured thinking we have just walked through together. Until next week.
Suneeta Modekurty
Founder, SANJEEVANI AI